Monitoring🔗
Several tools exist for high level monitoring your jobs which should be used to verify that your job is running as intended. These tools give hints towards problem areas and bottlenecks or underutilized resources (e.g. did you use all the GPUs you requested?).
After monitoring a job you can take a deeper dive and profile the application to find out more.
Job statistics🔗
The job_stats.py command returns you a link to a custom Grafana dashboard showing overview gauges of all your running jobs.
[chiajung@alvis1 ~]$ job_stats.py
https://grafana.c3se.chalmers.se/d/user-jobs/user-jobs?var-cluster=alvis&var-user=chiajung
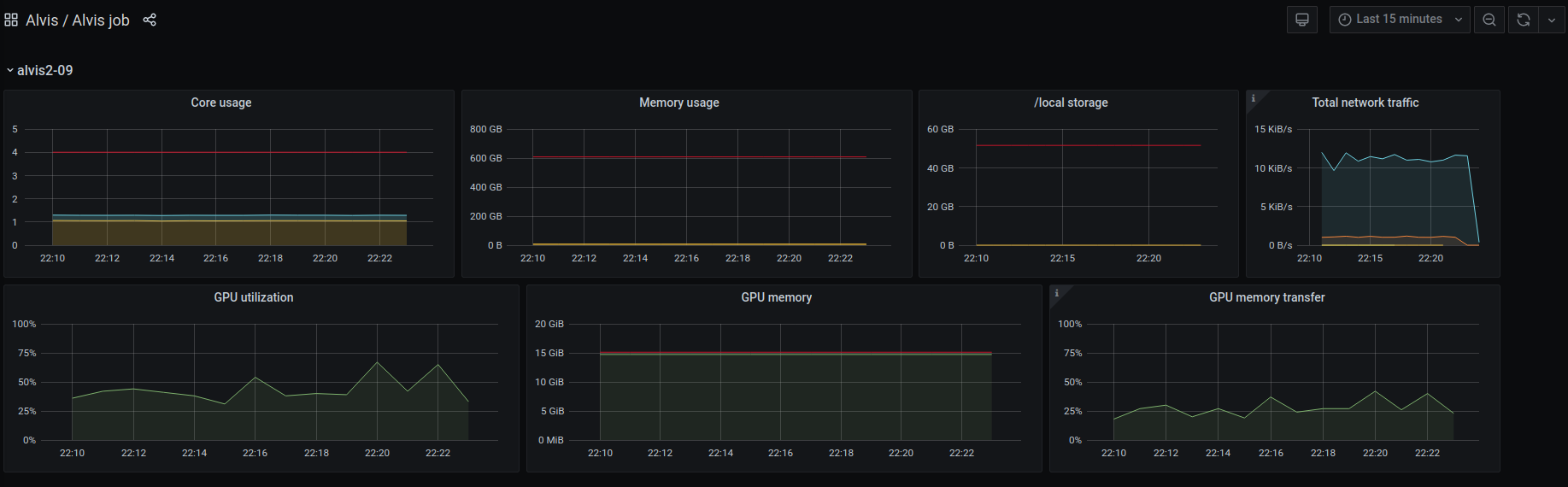
The command can also take a Slurm job ID and returns you a link to another Grafana dashboard showing you the real-time resource usage of the specific job.
[chiajung@alvis1 ~]$ job_stats.py 2463933
https://grafana.c3se.chalmers.se/d/gpu-job/gpu-job?var-jobid=2463933&from=1719838686000&to=1719840057000

** Note: Your job must have been started by Slurm before you run job_stats.py **
In the top right corner you can adjust the time interval. You can click and interact with each graph and highlight specific points in time.
The command works on both Vera and Alvis. For jobs running on Alvis, take special care to notice that you are actually utilizing all GPUs when you allocate several!
htop and nvtop and nvidia-smi🔗
If you ssh into the respective nodes for your job, you can use htop or nvtop commands to view CPU and GPU load respectively.
For monitoring the GPU usage you'll find recent versions of nvtop in the module system:
$ module spider nvtop
 .
.
You can also run nvidia-smi to view the current state of the GPUs, and power users could also use it for sampling metrics, e.g:
$ nvidia-smi --format=noheader,csv --query-compute-apps=timestamp,gpu_name,pid,name,used_memory --loop=1 -f sample_run.log